

BERT
Bidirectional Encoded Representation from Transformers
Google believes progress in natural language understanding, specifically BERT represents “the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search” and has been used in every one in ten searches in their search engine.
This is due to its capability of providing context to the search keywords. In addition to context, it is also capable of solving
Named entity determination.
Textual entailment next sentence prediction.
Coreference resolution.
Question answering.
Word sense disambiguation.
Automatic summarization.
Polysemy resolution.
Language translation.
How it works::
Previous models and their advancements in NLP
The state of the art models such as ELMo (Embeddings from Language Model) developed by the Allen Institute from University Washington and GPT(Generative Pre Training) from OpenAI made tremendous progress in the area of natural language understanding however both of these models were unable to address the complexity of solving the context of the sentence. In the English language often the target word’s (context word) meaning depends on the second part of the sentence. Since both methods’ approaches were unidirectional meaning they were only able to comprehend from either left to right OR right to left NOT both directions at the same time. Example:
“2019 brazil traveler to the USA need a visa.” Before BERT this search returned results about U.S. citizens traveling to Brazil. With BERT, search is able to grasp this nuance and know that the very common word “to” actually matters a lot here and returns Tourism and Visitor | US Embassy and Consulates in Brazil.
“do estheticians stand a lot at work.” Before BERT this search returned results Medical estheticians vs Spa estheticians and completely ignored the word “stand”, with BERT, the search is able to grasp the keyword stand and relate to the physical nature of the work.
BERT: It addresses the above limitation with the bidirectional approach. As shown in the below figure 1, which differentiate from the other two models.

Figure 1: Source: google paper(https://arxiv.org/pdf/1810.04805.pdf)
Architecture: BERT is a two-stage NLP model as shown in figure 2, the first stage uses unlabeled data to pre-train the model, and the second stage uses labeled data to fine-tune the model. Since it uses both unsupervised learnings (unlabeled data) and supervised learning(labeled data) it is called a hybrid model. It supports transfer learning which means pre-trained models from the first stage can be transferred without modifications to the second stage for fine-tuning.
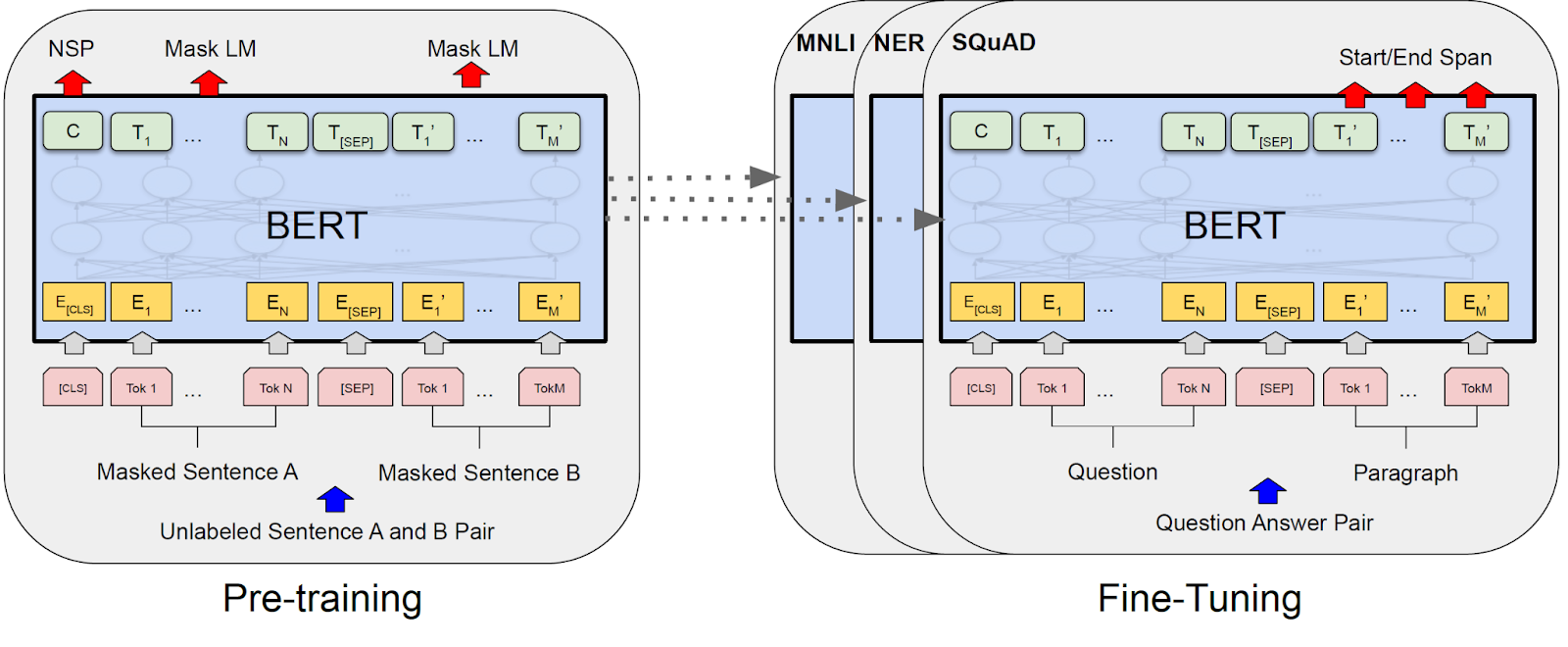
Figure 2: Source Google paper(https://arxiv.org/pdf/1810.04805.pdf)
Both stages use a similar kind of transformer neural network as shown in figure 3. However, the second stage has an additional layer for labeled data validation and varies depending on the task. Since these are transformer models, it provides high parallelism for robust training.
A typical transformer architecture

Figure 3: source Ashish Vaswani(https://arxiv.org/pdf/1706.03762.pdf)
BERT at large is built using 24 transformer blocks, 1024 hidden sizes, and 16 attention heads which can support Total Parameters of 340 Million equivalent to 16TPUs 96hurs for training and one TPU for inference. A typical transformer neural network will be shown in figure 3.
Text Preprocessing:
The pre-training corpus consists of BooksCorpus 800 Million words and English Wikipedia 2,500 Million words. Every input embedding is a combination of 3 embeddings and it is processed as shown in figure 4.
Position Embeddings: BERT learns and uses positional embeddings to express the position of words in a sentence. These are added to overcome the limitation of the Transformer which, unlike an RNN, is not able to capture “sequence” or “order” information
Segment Embeddings: BERT can also take sentence pairs as inputs for tasks (Question-Answering). That’s why it learns a unique embedding for the first and the second sentences to help the model distinguish between them. In the above example, all the tokens marked as EA belong to sentence A (and similarly for EB)
Token Embeddings: These are the embeddings learned for the specific token from the WordPiece token vocabulary

Figure 4: source: Google paper(https://arxiv.org/pdf/1810.04805.pdf)
Pre-training Tasks
BERT is pre-trained on two NLP tasks:
Masked Language Modeling
It uses bidirectional MLM(Masked/attention Language Model). MLM builds relationships between words. MLM means masking 15% of the words randomly and predicting the masked words using the softmax() function. This MLM is called bidirectional since it trains by looking at the left side of the target/masked/attention word and right side of the masked word and also uses the entire sentence to determine the context. The softmax function is an activation function in the output layer of neural network models that predict a multinomial probability distribution.
Next Sentence Prediction(NSP)
NSP is very important to BERT which builds the relationship between sentences. NSP is a binary classification task, the data can be easily generated from any corpus by splitting it into sentence pairs. The task is simple. Given two sentences – A and B, BERT has to determine whether B is the actual next sentence that comes after A or if it’s random. Consider that we have a text dataset of 100,000 sentences. So, there will be 50,000 training examples or pairs of sentences as the training data.
For 50% of the pairs, the second sentence would actually be the next sentence to the first sentence
For the remaining 50% of the pairs, the second sentence would be a random sentence from the corpus
BERT would label ‘is next’ for the first case and ‘NotNext’ for the second case
And this is how BERT is able to become a true task-agnostic model. It combines both the Masked Language Model (MLM) and the Next Sentence Prediction (NSP) pre-training tasks.
Performance:
BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, GLUE 80.5%, MultiNLI 86.7%, SQuAD 93.2%.
Leave a Reply